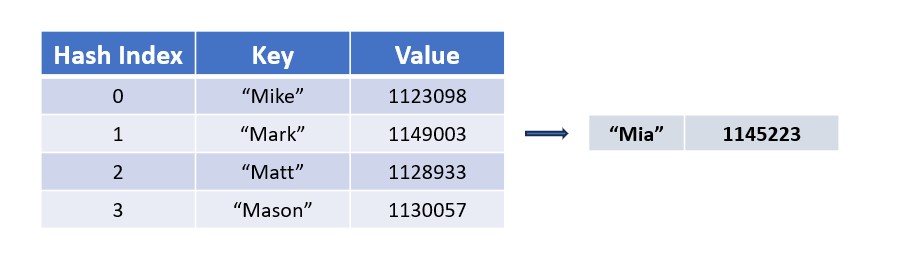
Definition:
A methodically stored collection of corresponding keys and values. Every key has a meaningful value that it is linked to (and typically meant to retrieve) and both are stored at a calculated location called a hash index.
Other common names for hash tables (some features may differ slightly from hash table):
Map
Dictionary
Hash Map
Associative Array
Real Life Example:
Think of hash tables as warehouse stores like Costco or Sam's Club. Every section in the store (outdoors, bakery, frosen foods, etc.) can be thought of as a hash index. The name of every item in the store can be thought of as a bunch of keys and the physical content of each item is the equivalent of a value. The placement of each item depends on its name, which relates it to a specified hash index (section in the store). In that section, the key (name of the item) and value (the physical item) are placed and stored.
Basic Properties:
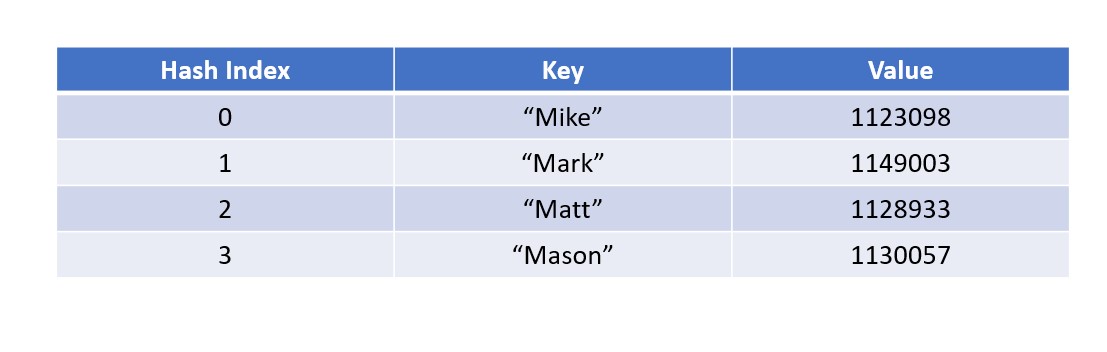
Hash Index: The index at which a particular key/value pair is stored assuming no hash collision (see fun fact). This index is calculated via a hash function, an expression that uses the name of the key to calculate a place (index) to store the pair at.
Key: The element needed to access the value stored behind it. Keys tend to be items or names. An example is an employee at a store's name. No two keys can be the same.
Value: The element stored behind a key. Values tend to be more specific information about the keys. An example is the employee mentioned above's ID number. Unlike keys, two different values can be the same.
Basic Hash Table Operations:
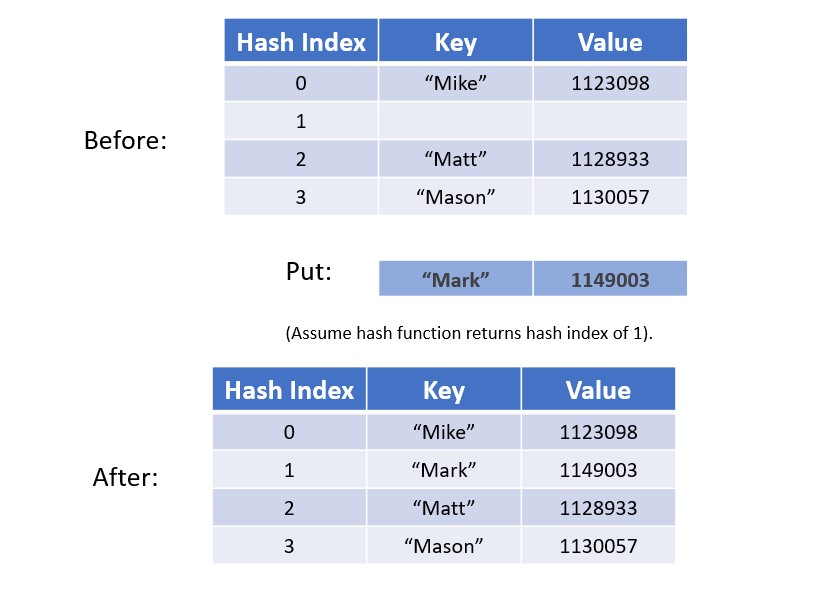
Adding a key/value pair. This is referred to as "putting" a pair into the hashtable.
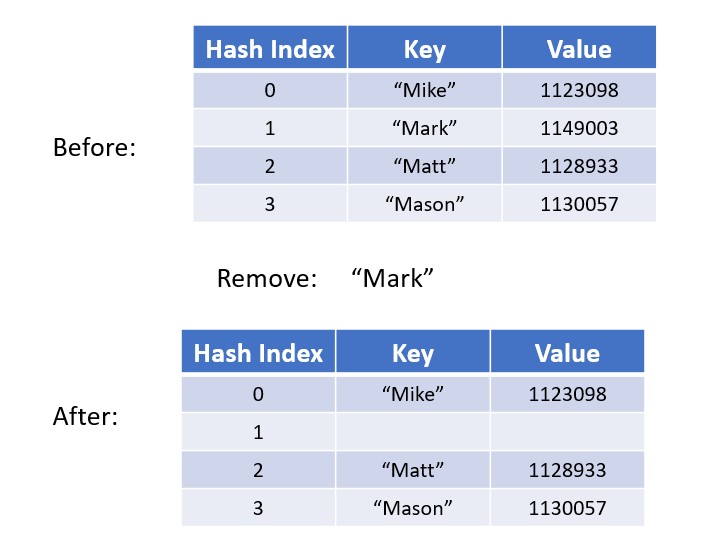
Removing a key/value pair from the hashtable. This is done by removing the key (the value is linked to the key so it is automatically deleted as well).
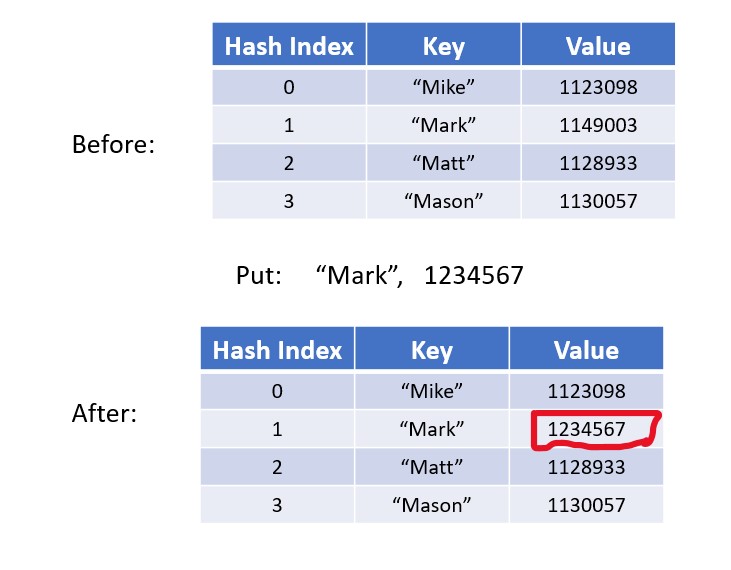
Changing the value of a key already in the hashtable.
Fun Fact: Despite hash tables being resizable, it is possible for a hash function to generate the same hash index for two different key/value pairs. This is a dilemma called hash collision. There are two common solutions to hash collision:
Separate Chaining: The key/value pair is stored at the initially calculated hash index but as a node in a Linked List containing the key/value pair(s) that were already there.
Open Addressing: The key/value pair is inserted at the closest empty hash index if it exists.
Commonly Used In:
Low level compiler/interpreter operations.
Cryptography/data security.
Spell check software.
Other Similar Data Structures:
Hash Set: A hash table that mimics a set by only storing unique keys behind hash indices (not key/value pairs with unique keys like a regular hash table).
Hash Tree: A tree that uses hashing to determine storage location for key/value pairs.
Linked Hash Map: A hash map where key/value pairs are linked together (via a Linked List) based on the order they were inserted regardless of assigned storage location.